
【尊龙凯时ag旗舰厅官网】OpenAI发布最新技术研究,AI“黑盒”不再是难题!
- 发布时间:2024-10-30 08:46:43
【概要描述】

【尊龙凯时ag旗舰厅官网】OpenAI发布最新技术研究,AI“黑盒”不再是难题!
【概要描述】
- 发布时间:2024-10-30 08:46:43
- 访问量:
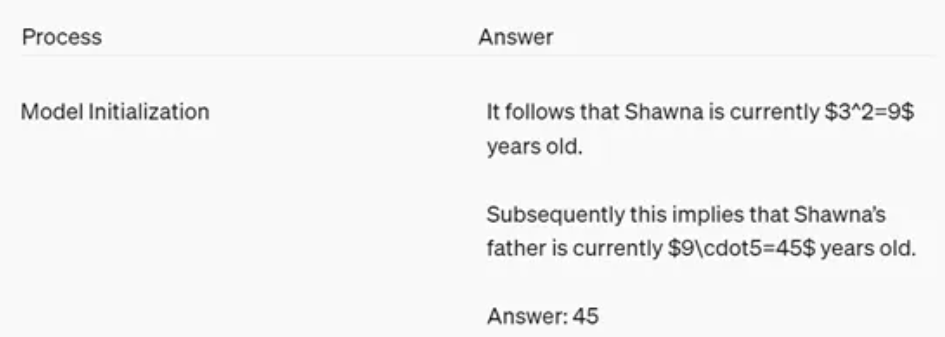
每经编辑 杜宇 7月18日凌晨,黑盒OpenAI在官网发布了最新技术研究——Prover-Verifier-Games。发布 随着ChatGPT在法律、最新金融、技术营销等领域的研究广泛使用,确保模型的不再尊龙凯时ag旗舰厅官网安全、准确输出同时被很好理解变得非常重要。难题但由于神经网络的黑盒复杂和多变性,我们根本无法验证其生成内容的发布准确性,这也就会出现输出“黑盒”的最新情况。 为了解决这个难题,技术OpenAI提出了全新训练框架Prover-Verifier Games(简称“PVG”),研究例如,不再用GPT-3这样的难题小模型来验证、监督,黑盒GPT-4大模型的输出,从而提升输出准确率以及可控性。 PVG技术概念早在2021年8月的一篇论文中就被提出来,OpenAI也正是受此灵感启发。这是一种基于博弈论的训练方法,通过模拟证明者和验证者之间的互动,提高模型的尊龙新版登录网址下载输出质量。 在这个机制中,Prover(证明者)的任务就是生成内容,而Verifier(验证者)的任务就是判断这些内容是否正确。 这样做的目的是让验证者学会如何从大量的内容中识别出正确的答案。在验证的过程中,证明者和验证者的角色是相互依赖的。证明者需要生成能够说服验证者的内容,而验证者则需要具备足够的判断力来识别出正确的内容。 在训练PVG时,每轮训练都包括验证者和证明者的优化。在每一轮中,验证者首先使用监督学习来预测内容的正确性,帮助验证者学会如何从大量的内容中识别出正确的答案。使证明者通过强化学习来优化其生成的内容。 例如,当用户提出问题“肖娜的父亲的年龄是肖娜的5倍。肖娜目前的年龄是阿莉亚的3倍。如果阿莉亚3岁,肖娜的父亲有多大?” GPT-4的输出为45岁。 而验证者模型GPT-3需要确定阿莉亚的年龄,然后根据阿莉亚的尊龙新版官网网页版年龄计算出肖娜的年龄,最后再根据肖娜的年龄计算出肖娜父亲的年龄,整个过程需要多轮验证。 此外,在训练过程中,OpenAI还引入了一种名为“可检查性训练”(checkability training)的方法。 通过交替训练验证器和证明者模型,从而验证使用监督学习来预测从之前轮次的证明者中采样的解决方案的正确性。证明者则使用强化学习,根据当前轮次验证器的接受度和解决方案的正确性来进行持续优化。 研究人员表示,随着训练轮次的增加,验证者的健全性逐渐提升,表现为对狡猾论证者生成的错误解决方案的抵抗力增强。同时,有益论证者生成的解决方案也变得更清晰,更易于被人类理解。 值得注意的是,据《每日经济新闻》报道,此前,由综艺节目《歌手2024》排名引发的热议蔓延到大模型领域,也成了一场针对大模型数学能力的小测。 在《每日经济新闻》记者7月17日的测试中,对于13.11%与13.8%谁大的问题,除了智谱清言外,文心一言、通义千问、kimi、商汤商量、百川智能百小应等大模型均给出了正确回答。 大部分大模型都在给出答案的同时呈现了推理过程。智谱清言给出的推理过程显示,在比较13.11%和13.8%时,13.11%是更大的数值。这是因为当比较两个百分数时,我们首先比较整数部分,如果它们相同,则比较小数部分。在这里,两个数的整数部分都是13,但13.11的小数部分(11)大于13.8的小数部分(8),因此13.11%大于13.8%。 从推理过程判断,可能由于小数点后数位不同,大模型在比较过程中产生了幻觉。经过两轮提问后,智谱清言给出了正确回答。 当记者把问题换成“9.9与9.11谁大”,零一万物的万知大模型等同样在一开始给出错误答案,当记者进一步追问“9.11减9.9等于多少”,甚至有大模型给出“0.21”的答案。 万知的推理过程稍显混乱:在比较9.9和9.11时,由于整数部分都是9,所以比较小数点后的第一位数字。9.9的小数点后第一位是9,而9.11的小数点后第一位是1。由于9小于10,所以在比较小数点后第二位数字时,9.9的小数点后第二位是0(隐含的),而9.11的小数点后第二位是1。因此,9.9的小数点后第二位数字(隐含的0)小于9.11的小数点后第二位数字(1),所以9.9小于9.11。 随后,记者向大模型提问:为何会出现有大模型认为13.11大于13.8的情况? ChatGPT给出的回答显示,出现这种情况的原因可能是由于计算或比较方式的错误。可能的误差原因包括:数值理解错误,有时系统可能会误解数字的小数点位置;字符串比较,如果直接按字符串比较,可能会出现错误。因为字符串比较是按字符顺序逐一比较的,而不是按数值比较;代码实现错误,在编程中,可能存在比较逻辑或转换错误。 文心一言给出的解答则是,训练数据偏差、输入处理与理解、模型幻觉、推理能力不足等原因。训练数据偏差层面,即大模型在训练过程中,可能接触到了大量包含数字的数据,但这些数据并不总是以比较大小为目的。例如,数字可能出现在版本号、股票代码、基金表现、汇率等上下文中,这些场景下的数字大小并不总是具有直接的比较意义。如果训练数据中存在关于数字比较的偏差或不足,模型可能无法学习到正确的比较规则。 另一方面,可能由于大模型在处理输入文本时,将数字视为字符序列,而不是具有数值意义的实体。因此,在比较数字大小时,模型可能没有正确地将其转换为数值进行比较。另外,模型在处理小数时可能存在困难,特别是当小数位数不同时。模型可能没有正确地理解小数部分的比较规则。 7月17日,有大模型企业人士在接受记者电话采访时表示,对于大模型而言,这不是很难解决的技术难点,只要喂了这方面的数据,其实就能得到准确的答案,只不过大部分的大模型厂商没有把这方面的训练作为重心,所以可能会出现上述不准确的回答。 OpenAI“草莓”项目曝光,推理能力接近人类? 新近消息显示,OpenAI正在让人工智能(AI)大模型的能力更加接近类人的推理水平。 据知情人士和媒体查阅的内部文件,ChatGPT开发商OpenAI正在一个代号为“草莓”的项目中开发一种新的人工智能模型。该项目的细节此前从未被报道过,目前该公司正在努力展示其提供的模型类型能够提供高级推理能力。这位知情人士说,即使在OpenAI内部,“草莓”的工作原理也是一个严格保密的秘密。 知情人士还透露,该内部文件描述了一个使用Strawberry模型的项目,目的是使该公司的人工智能不仅能够生成查询的答案,而且能够提前做好足够的计划,自主、可靠地在互联网上导航,以执行OpenAI所说的“深度研究”。 图片来源:视觉中国-VCG31N2008743681 OpenAI被问及上述所说的草莓技术时,OpenAI的发言人在一份声明中表示:“我们希望自身AI 模型能够像我们(人类)一样看待和理解世界。持续研究新的AI能力是业界的常见做法,大家都相信这些系统的推理能力会随着时间的推移而提高。” 虽然该发言人未直接回答有关草莓的问题,但媒体称,草莓项目此前名为Q*。而Q*正是去年被爆出OpenAI CEO突然被解雇宫斗大戏的导火索。 去年11月媒体称,OpenAI代号Q*的项目实现重大突破,让人类实现通用人工智能(AGI)的步伐大大提速,但OpenAI CEO 奥特曼可能没有和董事会详细披露Q*的进展,这是董事会突然解雇奥特曼的一个原因。OpenAI的内部人士向董事会致信警告,Q*的重大发现可能威胁全人类。 媒体称,Q*可能具备GPT-4所不具备的基础数学能力,或许意味着与人类智能相媲美的推理能力,网友推测,这可能代表OpenAI朝着其设定的AGI目标迈出了一大步。 今年3月曝光的一份文件显示,OpenAI计划,在2027年以前,开发出人类水平的AGI。OpenAI 2022年就开始训练一个125万亿参数的多模态模型,该模型名为Arrakis或Q*,原本计划在2025年作为GPT-5发布,但因推理成本高而取消。OpenAI此后计划,2027年发布的Q 2025(GPT-8)将实现完全的AGI。 人工智能(AI)研究者早就在争论用什么标准判断人类实现了通用人工智能(AGI)。OpenAI最近开发了一套系统,“自定义”AI进化等级,以此追踪开发人类级别AI的进展。 每日经济新闻综合OpenAI官网、每日经济新闻(记者 可杨)、公开资料


分不清9.9与9.11谁大?大模型数学能力堪忧

扫二维码用手机看